
Prometheus Blog Series (Part 2): Metric types
In Part 1 of this series, we talked about Prometheus metrics and how to make good use of labels to observe your applications under different segments and dimensions. This second part will look into more details in the 4 different types of Prometheus metrics: Counters, Gauges, Histograms and Summaries.
Counters: the only way is up
A great way to instrument the internal state of an application is to count whenever specific events happen, and expose this counter over time as a time series. Each data point of the time series is the value of the counter at the time the counter was observed.
The counter metric type works on a very strict assumption that it can only be incremented. When a service exposes a counter metric, it always starts at 0 and only goes up. Like all other metrics, each label combination is its own data-point and is incremented individually.
The best practice on naming counters is to using the _total suffix, e.g. batch_jobs_completed_total.
Observing counters over time
The absolute value of a counter is pretty irrelevant and should not be relied on - this is because counters do not preserve their value over application restarts. In a microservices architecture, instances of services are short-lived (e.g. rolling-updates, auto-scaling…), therefore counters will very often reset back to 0.
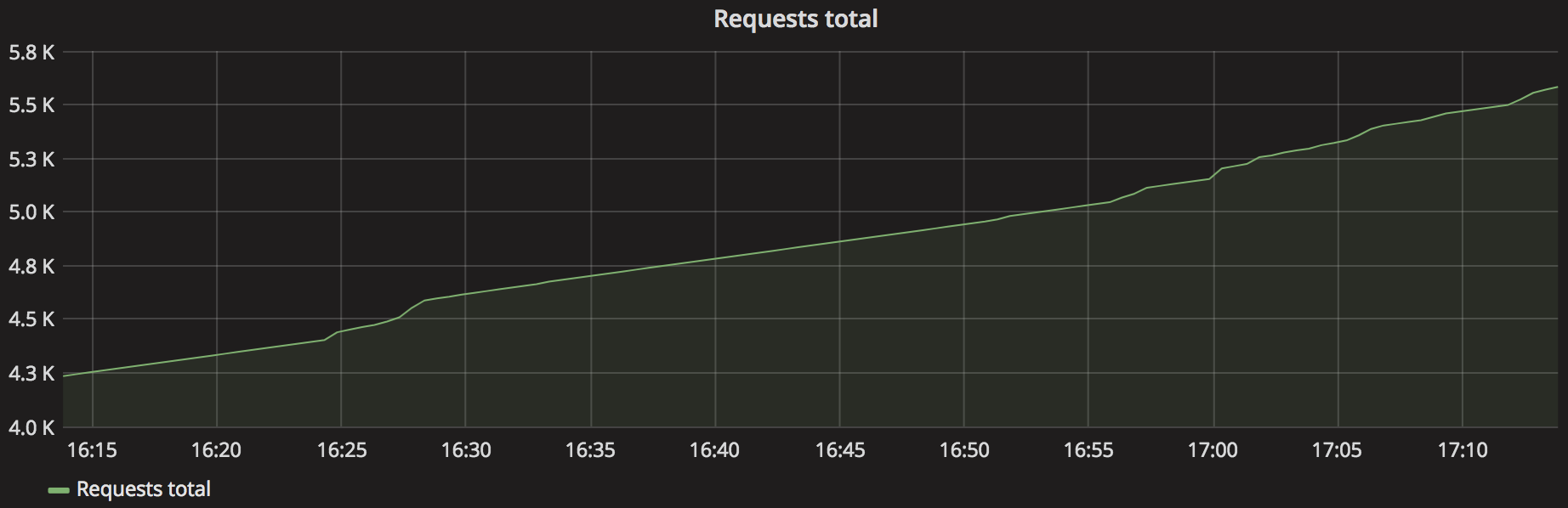
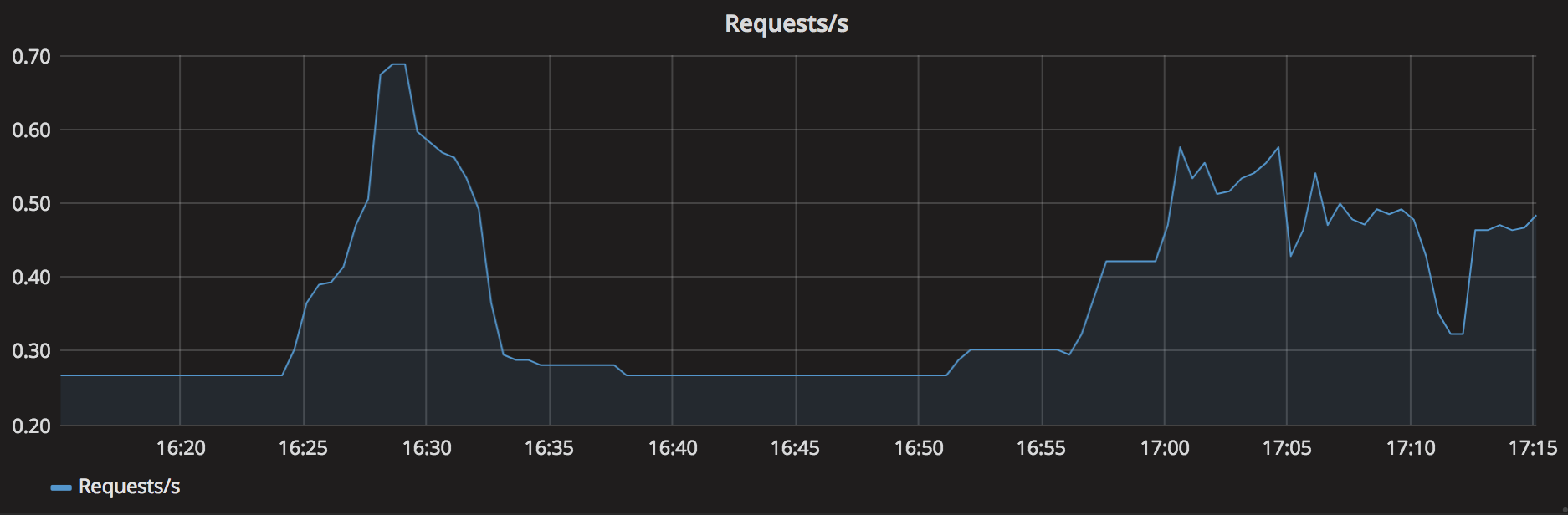
The real purpose of counters is actually in their evolution over time, which can be obtained through functions like rate() or irate(). These functions will automatically correct counter resets, allowing to calculate accurate rates even if some services restart.
# Total number of completed cleanup jobs by datacenter (will be affected by restarts)
sum(batch_jobs_completed_total{job_type="hourly-cleanup"}) by (datacenter)
# Number of completed cleanup jobs per second, by datacenter (not affected by restarts)
sum(rate(batch_jobs_completed_total{job_type="hourly-cleanup"}[5m])) by (datacenter)
Unlike the sum() function, rate() does not take in a metric, but a range vector (created by using the [ ] operator). A range vector contains all the data-points of the metric for the time-period specified. In the example above, [5m] will consider all data-points captured for our batch_jobs_completed_total metric for 5 minutes. Applying rate() to a range vector calculates the average rate of increase per second during that time-window. The longer the time-window, the smoother the rate() graph will be (potentially hiding local spikes).
Example of a requests counter (total and rate):
Gauges: instrumenting the current state
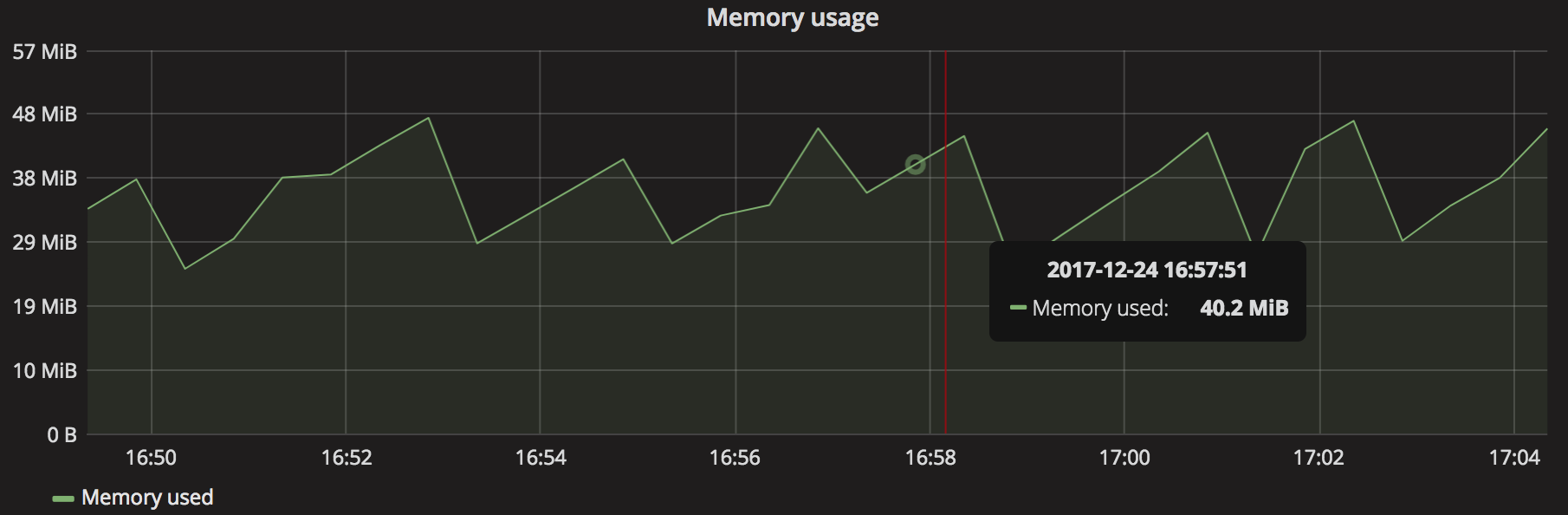
Not all application metrics can be covered by counters, as they might go up and down over time. Typically this will be the case of any metric exposing the current state of something, as opposed to how many things happened. Gauges can be used to track such metrics, for example:
# Amount of memory currently used
memory_bytes_used
# Number of jobs currently in queue
batch_jobs_in_queue{job_type="hourly-cleanup"}
Gauges are very easy to reason about - unlike counters, their absolute value is meaningful and can be used for graphs and alerts. Their evolution over-time can also be used, with functions like delta(), deriv() and even predicted using linear-regression with functions like predict_linear()
Histograms: sampling observations
When trying to observe the request latency of a service, the initial temptation can be to work with averages: they are simple to calculate over time using a total and a counter. Averages unfortunately have the big drawback of hiding distribution and prevent the discovery of outliers.
Quantiles are better measurement for this kind of metrics, as they allow to understand distribution. For example, if the request latency 0.5-quantile (50th percentile) is 100ms, it means that 50% of requests completed under 100ms. Similarly, if the 0.99-quantile (99th percentile) is 4s, it means that 1% of requests responded in more than 4s.
Quantiles are however quite expensive to calculate accurately, as they need the full set of observations (i.e. duration of each requests). Histograms make this simpler by sampling the observations in a pre-defined buckets. For example, a request latency Histogram can have buckets for <10ms, <100ms, <1s, <10s.
When creating an Histogram, it is important to think about what the buckets should be from the beginning. In most scenarios, the SLO for the metric in question can be a good place to start.
Prometheus can use these buckets to infer the quantiles using the histogram_quantile() function:
# Request duration 90th percentile
histogram_quantile(0.9, rate(http_request_duration_milliseconds_bucket[5m]))
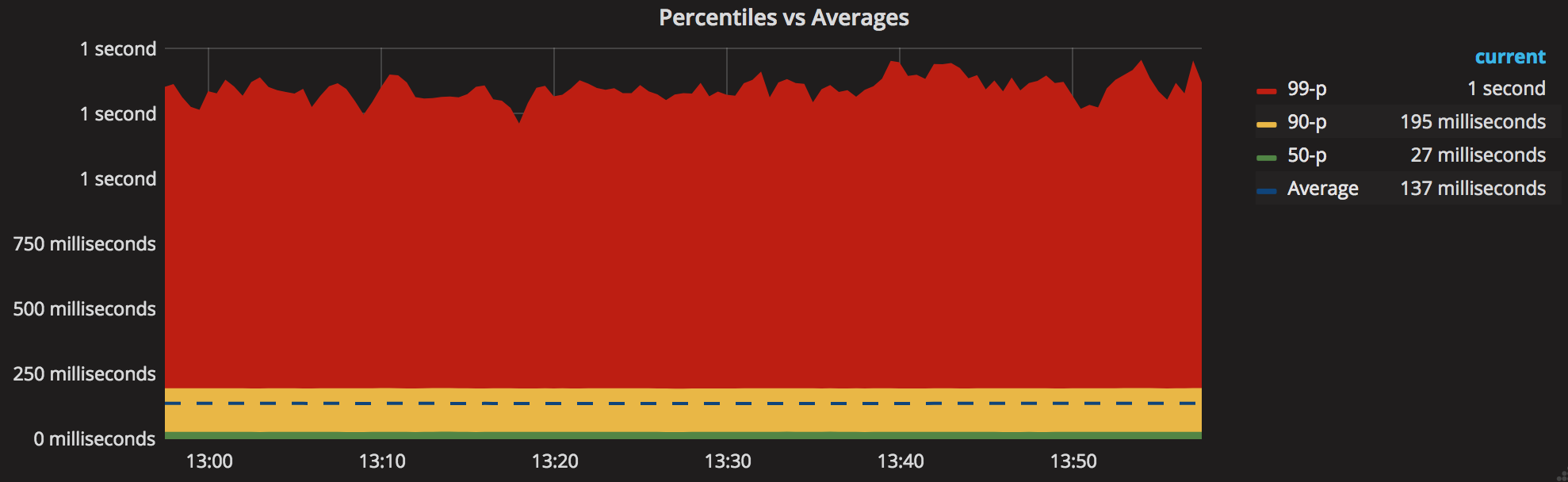
The graph aboves highlights how important distribution is to understand a metric like latency. If we imagine that this metric has an SLO of 150ms, a 137ms average latency might look acceptable; in reality 1 out of 10 requests completes in 193ms or more (90th percentile) and 1 out of 100 takes more than 1s!
More buckets means more labels
In practice, a Histogram will result in the creation of an additional metric (with the _bucket suffix), labeled with the upper bound of the bucket:
# HELP http_request_duration_milliseconds Http request latency histogram
# TYPE http_request_duration_milliseconds histogram
http_request_duration_milliseconds_bucket{le="100"} 3741
http_request_duration_milliseconds_bucket{le="200"} 4597
http_request_duration_milliseconds_bucket{le="400"} 4747
http_request_duration_milliseconds_bucket{le="800"} 4978
http_request_duration_milliseconds_bucket{le="1600"} 4991
http_request_duration_milliseconds_bucket{le="+Inf"} 5033
http_request_duration_milliseconds_sum 673428
http_request_duration_milliseconds_count 5033
Keeping in mind that each unique combination of labels is considered as a separate time-series, it is usually good practice to keep the number of buckets small, as well as the number of other labels on Histograms.
Summaries: client-side quantiles
Histograms and Summaries are very similar in the way that they expose the distribution of a given data set. While Histograms use sampling (with buckets) and estimate quantiles on the Prometheus server, Summaries are calculated on the client side (i.e. the service exposing metrics)
Summaries have the advantage of being more accurate for the pre-defined quantiles, however the client-side calculation can be expensive to do (while Histograms are basically just counters). One of the other drawbacks of Summaries is that they cannot be combined together, because quantiles cannot be averaged. Therefore, Summaries should only be used for metrics that make sense at an individual instance level (e.g. garbage collection times) or if the service in question is only going to have a single instance.
The pre-configured aspect of Summaries quantiles can also be a bit limiting, while Histograms allow to do this at the server level, without changing client instrumentation.
Example of the built-in Golang garbage collector summary:
# HELP go_gc_duration_seconds A summary of the GC invocation durations.
# TYPE go_gc_duration_seconds summary
go_gc_duration_seconds{quantile="0"} 4.274e-05
go_gc_duration_seconds{quantile="0.25"} 6.8508e-05
go_gc_duration_seconds{quantile="0.5"} 0.000275171
go_gc_duration_seconds{quantile="0.75"} 0.002328529
go_gc_duration_seconds{quantile="1"} 0.201453313
go_gc_duration_seconds_sum 0.467543895
go_gc_duration_seconds_count 92
What’s next?
This second part covered the different metric types Prometheus offers and in what situation they should (or should not) be used:
- Counters: use for counting events that happen (e.g. total number of requests) and query using
rate() - Gauge: use to instrument the current state of a metric (e.g. memory usage, jobs in queue)
- Histograms: use to sample observations in order to analyse distribution of a data set (e.g. request latency)
- Summaries: use for pre-calculated quantiles on client side, but be mindful of calculation cost and aggregation limitations
You should now have a better understanding of what Prometheus metrics are and how to query them… but how do these metrics get there in the first place? The next part of this series will get into the Prometheus pull model on how clients expose metrics and how Prometheus collects them.
If there is any specific subject you would like me to cover in this series, feel free to reach out to me on Twitter at @PierreVincent
More reading
Prometheus documentation:
Articles:
- Using
predict_linear()to alert on disk about to fill up, from robustperception.io
Looking to get more practical training with Prometheus?
I am regularly teaching workshops on Cloud Native monitoring with Prometheus & Grafana - don’t hesitate to get in touch with me (speaking@pvincent.io) for more info about running a workshop for your team or at your meetup/conference.