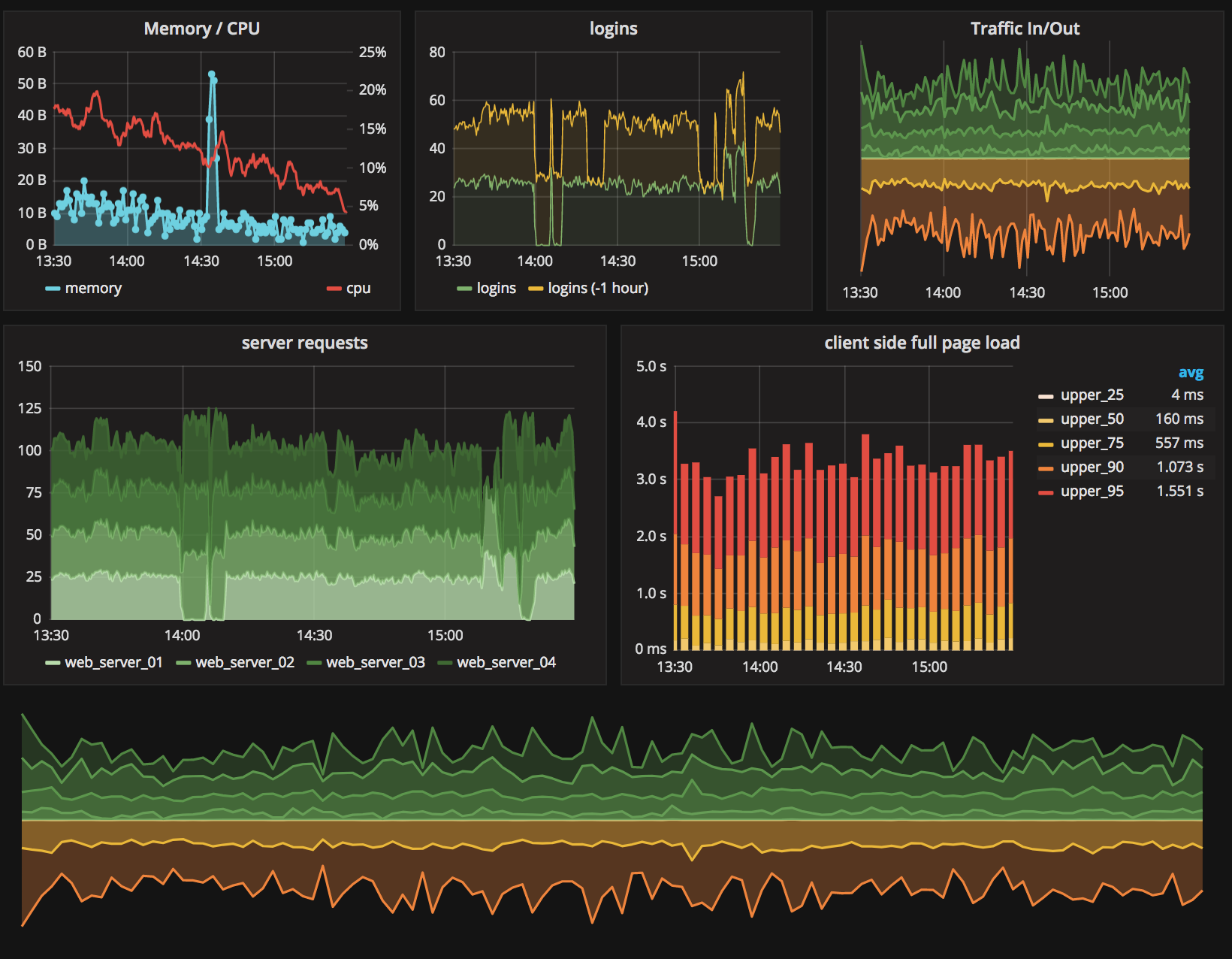
When I run workshops on practical monitoring with Prometheus, the same kind of questions usually get asked. Here are a few of them, with my answers and with pointers to other resources (articles, talks) to learn more.
Continue reading · 3 min read

When I run workshops on practical monitoring with Prometheus, the same kind of questions usually get asked. Here are a few of them, with my answers and with pointers to other resources (articles, talks) to learn more.
Continue reading · 3 min read

Instrumented applications bring in a wealth of information on how they behave. In the previous parts of this blog series, the focus has been mostly on getting applications to expose their metrics and on how to query Prometheus to make sense of these metrics. This exploratory approach is extremely valuable to uncover unknown unknowns, either pro-actively (testing) or reactively (debugging).
Metrics can also be used to help with things we already know and care about: instrumenting those things and knowing what is their normal state, then it’s possible to alert on situations that are judged problematic. Prometheus makes this possible through the definition of alerting rules.
Continue reading · 6 min read

So far in this Prometheus blog series, we have looked into Prometheus metrics and labels (see Part 1 & 2), as well as how Prometheus integrates in a distributed architecture (see Part 3). In this 4th part, it is time to look at code to create custom instrumentation. Luckily, client libraries make this pretty easy, which is one of the reasons behind Prometheus' wide adoption.
This post will go through examples in Go and Java. Prometheus has a number of other supported languages, through official libraries and community maintained ones.
Continue reading · 7 min read
In Part 1 and Part 2 of this series, we covered the basics of Prometheus metrics and labels. This third part will concentrate on the way Prometheus collects metrics and how clients expose them.
Continue reading · 4 min read
In Part 1 of this series, we talked about Prometheus metrics and how to make good use of labels to observe your applications under different segments and dimensions. This second part will look into more details in the 4 different types of Prometheus metrics: Counters, Gauges, Histograms and Summaries.
Continue reading · 6 min read
When it comes to monitoring tools in the last while, Prometheus is definitely hard to miss. It has quickly risen to be top of the class, with overwhelming adoption from the community and integrations with all the major pieces of the Cloud Native puzzle.
Throughout this blog series, we will be learning the basics of Prometheus and how Prometheus fits within a service-oriented architecture. This first post the series will cover the main concepts used in Prometheus: metrics and labels.
Continue reading · 4 min read
As engineers, we tend to have high expectations of product managers to justify the value of adding new features. What problem is this solving? How will we validate that we’re building the right thing? Is this the most important thing to work on right now?
These are great questions but interestingly we aren’t always applying the same rigor to the technical work.
Continue reading · 4 min read